Paper recap: Bag of Tricks for Image Classification with Convolutional Neural Networks
Bag of Tricks for Image Classification with Convolutional Neural Networks
He, Tong Zhang, Zhi Zhang, Hang Zhang, Zhongyue Xie, Junyuan Li, Mu, 2019
Research Topic
- Category (General): Deep Learning
- Category (Specific): Computer Vision
Paper summary
- Synthesize multiple effective methods that are briefly mentioned in litterature, in order to evaluate their impact on the final model accuracy through ablation study.
Issues addressed by the paper
- Find a combination of training procedure and model architecture refinements that improve model accuracy but barely change computational complexity.
- These “tricks” usually are minor ones (such as changing the stride of a convolutional layer), but create a big impact.
- These methods lead to significant accuracy improvement and combining them together can further boost the model accuracy. Transfer learning’s performance of these “boosted” model would be much better too.
Approach/Method
Training baseline
- Use the same training transformation (random sampling, random crop, random flip, hue/saturation/brightness, PCA noise, normalize).
- Only resize in validation set.
- Xavier initialization for weights of both convolutional and fully connected.
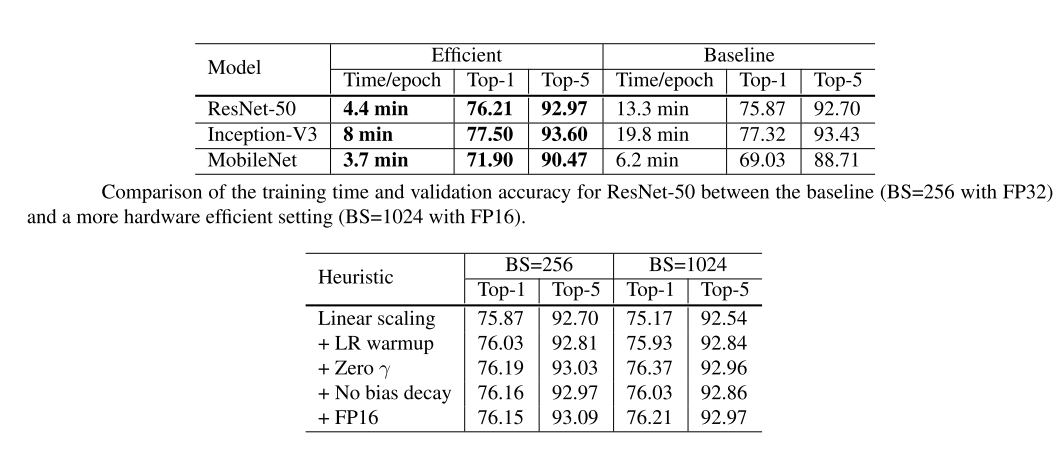
- Use NAG (Nesterov), 120 epochs, 8 GPUs, batch-size = 256.
- LR initialized to 0.1 and divided by 10 at the 30th, 60th, and 90th epochs.
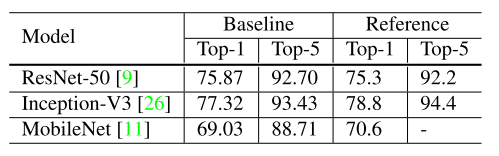
Efficient Training
- Larger training batch-size:
- Since we’re using mini-batch SGD, for the same number of epochs, training with a large batch size results in a model with degraded validation accuracy compared to the ones trained with smaller batch sizes.
- Some heuristics the help scale the batch size up like:
- Linear scaling learning rate: a large batch size reduces the noise in the gradient, so we may increase the learning rate to make a larger progress along the op- posite of the gradient direction.
- Learning rate warmup: Using a too large learning rate may result in numerical instability, so we gradually increase it.
- Zero \(\gamma\): we initialize \(\gamma = 0\) for all BN layers that sit at the end of a residual block. Therefore, all residual blocks just return their inputs, mimics network that has less number of layers and is easier to train at the initial stage.
- No bias decay: Only apply to the regularization to weights to avoid overfitting.
- Low-precision training:
- Use FP16 to train since new hardware may have enhanced arithmetic logic unit for lower precision data types.
Model Tweaks
- A model tweak is a minor adjustment to the network architecture (changing the stride of convlution layer).
- Such a tweak barely changes the computational complexity but might have a non-negligible effect on the model accuracy.
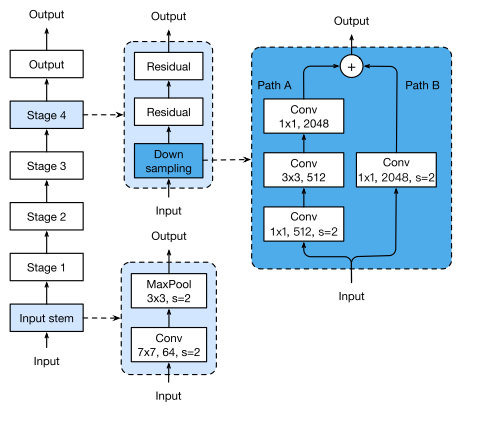
- Take a closer look at Resnet architecture:
- Resnet network consists of an input stem (reduces the input W/H by 4 times and increases its channel size to 64), four subsequent stages and a final output layer.
- Resnet has a basic block called Bottleneck Block (downsampling block). There are 2 paths in the block:
- Path A: has three convolutions, whose kernel sizes are 1×1 (stride 2 - halve the input size), 3×3 and 1×1 (output channels x4 the previous 2), respectively.
- Path B: uses a 1×1 convolution (stride of 2) to create the same output shape as path A, so we can sum outputs of both paths to obtain the output of the downsampling block.
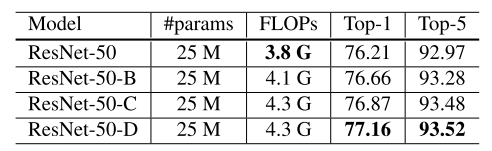
- There are 3 tweaks mentioned is this paper:
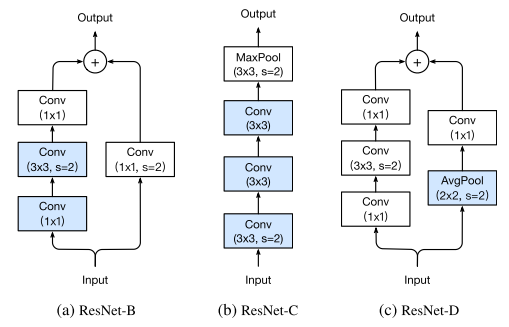
- Resnet-B: modifies downsampling block
- Observation: convolution in path A (original) ignores \(\frac{3}{4}\) of the input feature map because it uses a kernel size 1×1 with a stride of 2.
- Tweak: Change stride of the first two conv, so no information is ignored.
- Resnet-C: modifies input stem
- Observation: the computational cost of a convolution is quadratic to the kernel width or height (A 7 × 7 convolution is 5.4 times more expensive than a 3 × 3 convolution).
- Tweak: replacing the 7×7 convolution with 3 conservative 3 × 3 convolutions, with the first and second convolutions have their output channel of 32 and a stride of 2, while the last convolution uses a 64 output channel.
- Resnet-D: modifies downsampling block
- Observation: Inspired by Resnet-B, 1×1 convolution in the path B also ignores \(\frac{3}{4}\) of input feature maps.
- Tweak: Change stride to 1 and add a 2×2 average pooling layer with a stride of 2 before the convolution, since it works well in practice and impacts the computational cost little.
Training Refinements
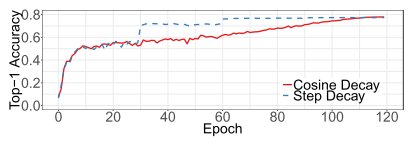
- Cosine Learning Rate Decay:
- Method: Same as my previous post.
- Result: Compared to the step decay, the cosine decay starts to decay the learning since the beginning but remains large until step decay reduces the learning rate by 10x, which potentially improves the training progress.
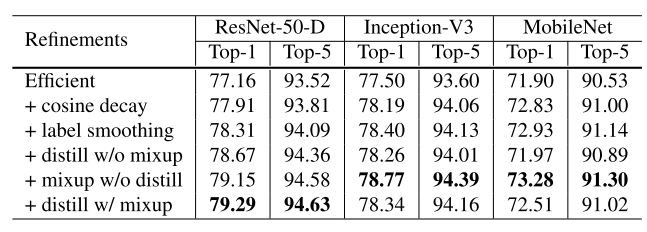
- Label Smoothing:
- Method: Same as my previous post.
- Result: Compared to the softmax, it encourages a finite output from the fully-connected layer and can generalize better.
- Knowledge Distillation: skipped.
- Mixup: Same as my previous post.
Conclusions
Rating

Papers needs to conquer next 👏👏👏
- Focal Loss